Gli scienziati di Amazon Alexa dimostrano che l’intelligenza artificiale più grande non è sempre migliore
Gli scienziati di Amazon dimostrano che l'IA più grande non è sempre migliore
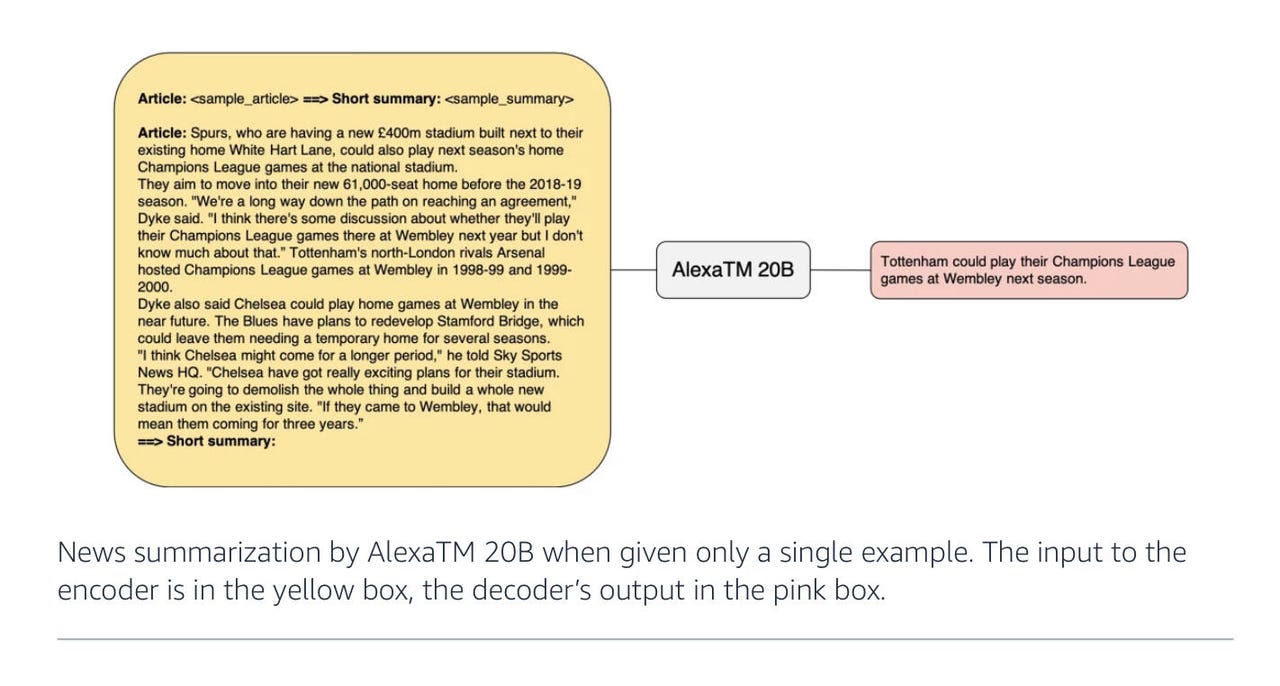
Un compito semplice, ridurre tutte le parole in un articolo in una sequenza compatta di parole che spiega il punto centrale dell’articolo, è tra i compiti di riferimento nell’apprendimento profondo. È qui che gli scienziati dell’IA di Amazon Alexa dicono di poter superare gli sforzi di programmi informatici molto più grandi di DeepMind, Google, Meta, OpenAI e altri. Il lavoro ha implicazioni per l’uso dell’energia e l’efficienza delle emissioni di carbonio.
Oggi, due filoni di ricerca dominano fortemente l’apprendimento automatico: rendere i programmi più generali nel loro approccio (per gestire qualsiasi possibile compito) e renderli più grandi.
Le reti neurali più grandi, misurate in base ai loro parametri o “pesi”, superano i mezzo trilione di pesi. Modelli come il Pathways Language Model di Google, o PaLM, e il Megatron-Turing NLG 530B di Nvidia e Microsoft sono tra i più grandi, con rispettivamente 540 miliardi e 530 miliardi di parametri. Più parametri ha un programma, in generale, maggiore è la quantità di potenza di calcolo che consuma per l’addestramento e anche per l’esecuzione delle previsioni, ciò che viene chiamato inferenza.
Intelligenza Artificiale
- 7 suggerimenti avanzati per la scrittura di prompt di ChatGPT che devi conoscere
- I 10 migliori plugin ChatGPT del 2023 (e come sfruttarli al meglio)
- Ho testato molti strumenti AI per il lavoro. Questi sono i miei 5 preferiti finora
- Umano o bot? Questo gioco del test di Turing mette alla prova le tue capacità di individuazione dell’IA
I conoscitori di AI insistono sul fatto che il conteggio dei parametri sta sicuramente salendo verso l’alto e verso la destra, verso un trilione di parametri e oltre nel futuro non troppo lontano. La cifra di 100 trilioni è un tipo di obiettivo magico perché si crede che sia il numero di sinapsi in un cervello umano, quindi serve come un punto di riferimento di sorta.
Inoltre: Nvidia chiarisce l’affermazione sulla scala di Megatron-Turing
- Il vero obiettivo dell’IA potrebbe non essere più l’int...
- L’illusione della persona Esisti realmente sui social media?
- Il Metaverso è un dilemma dei diritti umani
Allo stesso tempo, c’è un fervore nel creare reti neurali profonde che possano essere il più generali possibile. Per gran parte della storia dell’apprendimento automatico degli ultimi 40 anni, i programmi erano specializzati per compiti come il riconoscimento delle immagini o il riconoscimento della voce. Questo è cambiato negli ultimi anni, con sempre più programmi che si offrono di essere generalisti, come il Perceiver AR di DeepMind e un altro programma di DeepMind, Gato, definito “un agente generalista” capace di risolvere una miriade di compiti.
La tendenza alla generalizzazione è stata rafforzata dalle osservazioni dei pionieri dell’apprendimento automatico come Richard Sutton, che ha osservato che “storicamente, i modelli generici che sono migliori nel sfruttare il calcolo hanno anche tendenza a superare alla fine approcci specifici del dominio più specializzati”.
Inoltre: ‘Gato’ di DeepMind è mediocre, quindi perché l’hanno costruito?
Eppure, ci sono risultati di apprendimento profondo che talvolta vanno nella direzione opposta: contro i giganteschi e generali verso quelli più economici e leggermente focalizzati, se non specializzati.
A differenza di quei mega-sforzi, la scorsa settimana i ricercatori di Amazon hanno presentato un programma di rete neurale con solo 20 miliardi di parametri che supera alcuni dei modelli più grandi e più generali su alcuni importanti compiti di riferimento dell’apprendimento profondo, come ad esempio come riassumere un articolo.
Nel documento “AlexaTM 20B: Apprendimento a poche istanze utilizzando un modello Seq2Seq multilingue su larga scala”, pubblicato la scorsa settimana su arXiv, l’autore Saleh Soltan e i colleghi di Amazon Alexa AI mostrano che 20 miliardi di parametri sono sufficienti per battere modelli più grandi come PaLM su determinati compiti, come riassumere un articolo in poche frasi.
Oltre al documento, Soltan ha scritto un post sul blog sull’argomento.
Il lavoro di Amazon fa parte di una tendenza generale nella recente letteratura di trovare alternative all’aumento delle dimensioni. Un documento pubblicato la scorsa settimana da Meta (proprietari di Facebook e Instagram) intitolato “Apprendimento a poche istanze con modelli linguistici potenziati da recupero” è un buon esempio. Descrive un modello linguistico chiamato Atlas che ha solo 11 miliardi di parametri ed è addestrato utilizzando solo 64 punti dati di esempio.
Come con AlexaTM 20B, il programma Atlas batte PaLM di gran lunga, scrivono gli autori, anche con solo 64 esempi. La chiave di Atlas è combinare il modello linguistico pre-addestrato con la capacità di recuperare informazioni da fonti online, come Wikipedia, come se stessi chiamando un amico per la risposta.
Inoltre: DeepMind’s Perceiver AR: Un passo verso una maggiore efficienza dell’IA
Nel caso di AlexaTM 20B, gli autori di Amazon utilizzano tre modifiche per raggiungere i loro punteggi.
Diagramma Amazon 2022 AlexTM 20B
La prima modifica interessante è tornare alle basi e ripristinare qualcosa che è stato rimosso dai recenti giganteschi modelli linguistici. La base di AlexaTM 20B è la stessa di PaLM, GPT-3 e altri, un codificatore-decodificatore di tipo Transformer – l’approccio inaugurato nel 2017 dagli scienziati di Google Ashish Vaswani e colleghi.
Il Transformer utilizza unità chiamate “auto-attenzione” per ottenere un punteggio di probabilità su come ogni parola può essere trovata nel contesto di altre parole. Quel punteggio viene poi utilizzato per riempire i vuoti quando si predicono le parole per formare blocchi di testo significativi.
Nel caso di AlexaTM 20B, Soltan e colleghi si discostano in modo critico da PaLM, GPT-3 e altri discendenti giganteschi del Transformer originale. Questi modelli più recenti si sono sbarazzati di metà del Transformer, quella che viene chiamata il codificatore (la parte che mappa i dati di input in stati nascosti per poi essere decodificati in una risposta). Invece, PaLM e GPT-3 uniscono l’input al decodificatore, per formare un programma ridotto che è un modello “solo-decoder”.
Il team di Alexa reintegra il codificatore nel programma. La loro affermazione è che avere entrambi gli elementi aiuta a migliorare l’accuratezza in quello che viene chiamato “de-noising”, ovvero ricostruire una frase originale in cui alcune parole sono state omesse.
Nel modello “solo-decoder”, la probabilità condizionale del testo predetto si basa solo su ciò che è venuto prima. Nella versione completa codificatore-decodificatore, al contrario, il modello valuta le probabilità in entrambe le direzioni: ciò che è venuto prima di una determinata parola e ciò che segue. Questo è utile in compiti in cui non si sta solo generando l’elemento successivo in una frase, ma si sta anche facendo cose come il confronto parola per parola, ad esempio nei compiti di traduzione da una lingua all’altra.
Modelli “solo-decoder” di Amazon 2022 AlexTM 20B
Inoltre: La mastodontica opera di traduzione multilingue di Meta continua a inciampare nel greco, armeno, oromo
Come scrivono, “AlexaTM 20B raggiunge un nuovo state-of-the-art dell’82,63% nell’impostazione zero-shot nella modalità de-noising. Il motivo principale per cui la modalità de-noising funziona meglio per questo compito è che nella modalità de-noising, l’input viene ripetuto nel codificatore e nel decodificatore, consentendo al modello di utilizzare pienamente sia il codificatore che il decodificatore per trovare la migliore risposta.”
La seconda cosa che gli autori aggiungono è addestrare il modello con quello che viene chiamato “causal language modeling”. CLM, per abbreviare, è il compito utilizzato in GPT-3 e in altri Transformer solo-decoder. Rappresenta specificamente ogni parola come dipendente solo dalle parole che sono venute prima – una dipendenza sequenziale unidirezionale che viene addestrata a generare frasi basate su un prompt iniziale.
Gli autori mescolano il compito di de-noising con il compito causale nell’addestramento di AlexaTM 20B, con il de-noising che rappresenta l’80% dell’attività di addestramento e il modeling causale l’altro quinto.
Il vantaggio dell’aggiunta del modeling causale è che, simile a GPT-3, aiuta nell'”apprendimento in contesto”. L’apprendimento in contesto è una categoria ampia che include tutti i modelli capaci di apprendimento zero o few-shot. Ciò significa che il programma non ha conoscenze specifiche del dominio; gli viene semplicemente fornito un prompt di esempio e il programma fa una previsione coerente con il tipo di domanda posta.
Grazie a quel regime di addestramento ibrido, AlexTM 20B non solo si comporta bene nella ricostruzione delle frasi – il compito di de-noising, ma è anche “il primo modello seq2seq multilingue in grado di apprendimento in contesto”, scrivono gli autori. È un programma ibrido, in altre parole.
La terza modifica interessante di Soltan e colleghi è aumentare enormemente il numero di punti dati inseriti nel programma durante l’addestramento. Inseriscono un trilione di “tokens”, singoli pezzi di dati, durante l’addestramento; più del triplo di quelli ricevuti da GPT-3. I set di dati di addestramento in questo caso consistono in voci di Wikipedia e anche in ciò che viene chiamato mC4, un set di dati per l’addestramento di Transformer introdotto l’anno scorso da Linting Xue e colleghi di Google. Si basa su testo in linguaggio naturale in 101 lingue provenienti da fonti di dati web raccolti da Common Crawl.
Inoltre: Sentient? Google LaMDA sembra un chatbot tipico
L’utilizzo di una quantità molto grande di dati di addestramento in input è uno degli elementi chiave del lavoro di Alexa. Soltan e il suo team hanno deciso di seguire questa strada, scrivono, basandosi su un’osservazione fatta da Jordan Hoffman e colleghi di OpenAI, come pubblicato in un articolo lo scorso marzo, “Training compute-optimal large language models” (“Addestramento di modelli di linguaggio ottimali in termini di calcolo”).
In quel documento, Hoffman e i suoi colleghi concludono che “i modelli di linguaggio di grandi dimensioni attuali sono significativamente sottoposti ad addestramento insufficiente, una conseguenza del recente focus sull’aumento delle dimensioni dei modelli di linguaggio mantenendo costante la quantità di dati di addestramento”. Prendendo in considerazione una vasta gamma di modelli di linguaggio di diverse dimensioni e testandoli tutti con quantità variabili di token in input, gli autori hanno concluso che “per un addestramento ottimale in termini di calcolo, la dimensione del modello e il numero di token di addestramento dovrebbero essere scalati in modo uguale”.
Di conseguenza, AlexaTM 20B non è solo parsimonioso, ma mira a dimostrare che un minor numero di parametri può essere bilanciato con un maggior numero di dati di addestramento per ottenere prestazioni convincenti.
ENBLE Consiglia
Quale Amazon Echo comprare? Come scegliere il miglior dispositivo Alexa per le tue esigenze
Amazon ora ha un intero esercito di dispositivi Echo. Alcuni ti ascoltano. Alcuni ti osservano anche. Quale dovresti scegliere? Ti aiutiamo a decidere.
Incidentalmente, gli autori si impegnano anche a modellare la maggior parte dell’input come testo parlato naturale, eliminando la capitalizzazione e la punteggiatura, che ha importanza in un contesto di Alexa. “Includiamo più testi parlati che scritti per soddisfare i nostri casi d’uso interni”, scrivono.
Alcune delle tecnologie del team di intelligenza artificiale di Alexa sono utilizzate nei prodotti Alexa, anche se Amazon ha dichiarato a ENBLE in una e-mail che il gruppo “conduce anche ricerche prospettiche”. Il modello AlexaTM 20B, secondo Amazon, “è principalmente un progetto di ricerca in questa fase”.
Inoltre, Amazon ha aggiunto: “È possibile che questo modello venga impiegato in produzione in futuro, ma verrà utilizzata solo una versione modificata con protezioni per sviluppare funzionalità e prodotti di Alexa”.
Inoltre: Il massiccio lavoro di traduzione linguistica di Google identifica dove commette errori
Gli autori addestrano il modello AlexaTM 20B “per 120 giorni su 128 GPU Nvidia A100 per un totale di 500k aggiornamenti con una dimensione di batch accumulata di 2 milioni di token (per un totale di 1 trilione di aggiornamenti di token)”, scrivono.
Potrebbe sembrare molto, ma è meno di PaLM, che è stato addestrato da Google su due dei suoi pod TPU di quarta generazione, composti da 3.072 chip TPU in ogni pod, collegati a 768 computer host.
Come hanno osservato gli autori di Google Aakanksha Chowdhery e il suo team ad aprile, questo era “la configurazione TPU più grande descritta fino ad oggi”.
I risultati sono spiegati dettagliatamente nei risultati dei test specifici. Soltan e il suo team pongono un’attenzione particolare al successo in particolari compiti rispetto a ogni possibile compito. Ad esempio, Soltan e il suo team osservano che “AlexaTM 20B si comporta meglio o allo stesso livello del modello di decodifica densa più grande fino ad oggi (ossia PaLM 540B) nella sintesi sia in modalità 1-shot che di fine-tuning”. Questo è vero in particolare in un compito di sintesi di paragrafi noto come MLSum; in tedesco, spagnolo e francese, AlexaTM 20B batte facilmente PaLM.
Il test di benchmark MLSum, introdotto nel 2020 dal Centre National de la Recherche Scientifique della Francia, comprende 1,5 milioni di articoli dai giornali. Il compito consiste nel far uscire da un modello di linguaggio alcune frasi di testo che esprimano l’idea esposta nell’intero articolo. Questo richiede ovviamente molta sintesi, riducendo centinaia di parole a forse qualche decina.
Amazon
- Come trasformare il tuo vecchio tablet Fire in un Echo Show
- Scambia i tuoi vecchi dispositivi con buoni regalo Amazon. Ecco come
- I migliori tablet Amazon: Gioca con il Fuoco
- Recensione del Kindle di Amazon: 7 mesi dopo, è quasi perfetto
In un quarto test, XSum, eseguito in inglese, il modello AlexaTM 20B è arrivato secondo, superando una versione di PaLM che era più grande di AlexaTM 20B ma più piccola della versione da 540 miliardi di parametri di PaLM.
Anche se eccelle nella sintesi, il modello AlexTM 20B presenta delle carenze in altri compiti. Ad esempio, testato su set di dati di “ragionamento” (come MultiArith) e compiti di “catena di pensiero” (che sono problemi aritmetici molto semplici espressi in linguaggio naturale), il programma è molto distante da ciò che viene realizzato con modelli molto più grandi come GPT-3.
Anche: Il futuro dell’IA è una storia di software, afferma il CEO di Graphcore
Scrivono Soltan e il suo team, “AlexaTM 20B si comporta leggermente meglio rispetto a modelli di dimensioni simili, tuttavia non abbiamo osservato il guadagno che modelli molto più grandi come GPT3 175B mostrano con prompt speciali,” che significa, indizi dati al programma sul prossimo passo in un problema.
“I risultati indicano che aumentare i parametri del modello è cruciale per ottenere buoni risultati nei compiti di ‘ragionamento’, come precedentemente dimostrato […] nelle architetture solo-decoder utilizzando modelli Instruct-GPT3.”
Concentrandosi sulle attività di successo, come la sintesi, la principale conclusione a cui Soltan e il suo team arrivano è che il loro approccio misto all’addestramento del programma – utilizzando sia obiettivi di de-noising che modellazione causale del linguaggio – è la chiave per rendere le cose più efficienti.
“Ciò suggerisce che il pre-training misto e non necessariamente un addestramento multi-task aggiuntivo […] è la chiave per addestrare modelli di linguaggio su larga scala (LLM) basati su seq2seq robusti,” scrivono.
Tornando alla domanda originale sulla dimensione, come è stato osservato in molti contesti, l’uso energetico di programmi AI sempre più grandi è una preoccupazione etica all’interno delle pratiche di AI. Gli autori presentano un forte caso per la pertinenza del loro approccio più efficiente.
Anche: Etica dell’IA: vantaggi e rischi dell’intelligenza artificiale
Perché l’AlexaTM 20B “è molto più piccola in termini di dimensioni rispetto a modelli come GPT3 175B, ma raggiunge prestazioni simili o migliori in diverse attività”, scrivono, “l’impatto ambientale in corso dell’uso di AlexaTM 20B per l’inferenza è molto inferiore rispetto a quello di modelli più grandi (circa 8,7 volte inferiore).”
Aggiungono, “Di conseguenza, nel tempo, AlexaTM 20B ha un’impronta di carbonio inferiore.”
Gli autori offrono una tabella di statistiche che mostra l’impronta di carbonio relativa, e ci sono differenze significative nei numeri.
Questa è una tabella di confronto delle impronte di carbonio di AlexaTM 20B Amazon 2022.
Questa tabella delle impronte di carbonio è forse l’aspetto più interessante di tutto questo. Sembra che la ricerca sull’apprendimento profondo cercherà di ottenere punteggi per le valutazioni ambientali, al fine di mostrare quanto efficiente dal punto di vista energetico possa essere un determinato approccio. Questo è in linea con l’aumento del focus mondiale sui fattori “ESG”, che significa fattori ambientali, sociali e di governance, in tutte le cose.
Ciò potrebbe significare che essere ecologicamente consapevoli è diventato in qualche modo parte dell’obiettivo della ricerca sull’IA mainstream.
Anche: AI in sessanta secondi